
28-Week Real-World AWS DevOps Bootcamp with MLOps and AIOps
Batch Details
- Fee: ₹ 60,000 ($700)
- Starting On 18th July
- 28 Weeks, 56 Classes, 180 min each
- Saturday & Sunday, 7.30 PM IST- 10.30 PM IST
- Instructor: Akhilesh Mishra
- Format: Live Classes (English)
- Life Time Access
Demo Classes
- Starting On 18th July
- 28 Weeks, 56 Classes, 180 min each
- Saturday & Sunday, 7.30 PM IST- 10.30 PM IST
- Instructor: Akhilesh Mishra
- Format: Live Classes (English)
- Life Time Access
India
Global
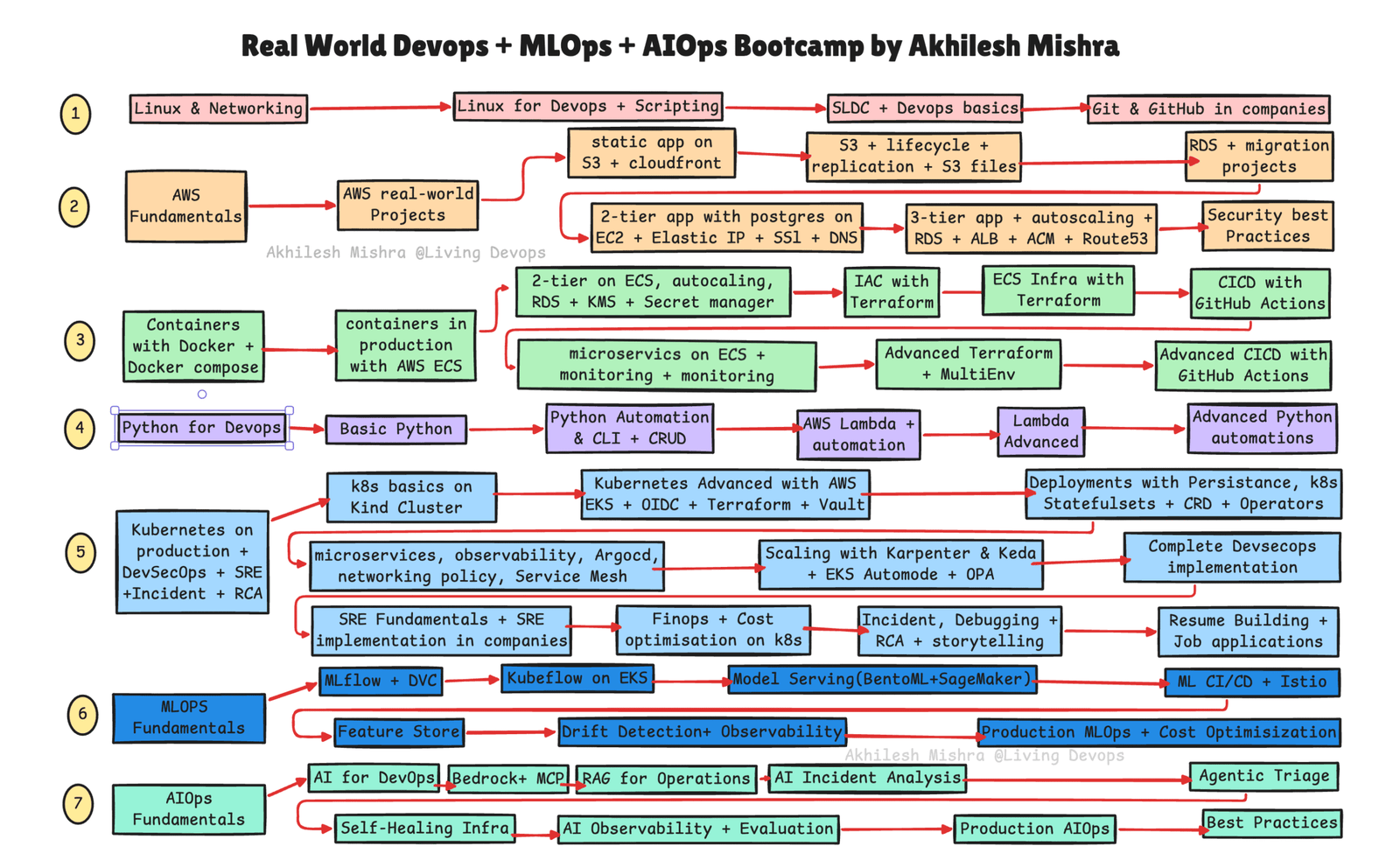
Production-Grade AWS DevOps + SRE + DevSecOps + MLOps + AIOps Bootcamp
Production-grade bootcamp that teaches you DevOps + SRE + DevSecOps + Python + MLOps + AIOps, with real-world projects, live troubleshooting, incident response, and RCA.
Spend 28 weeks building production-grade systems on AWS and troubleshooting real incidents live.
I will also teach you AI-assisted troubleshooting throughout the bootcamp: how to debug real failures faster with AI copilots, and how to get genuinely better at working with AI in your day-to-day engineering work.
After each class, recordings, code, and resources will be provided.
Total Classes: 56
Class Duration: 3 hours each
Format: Live Online Classes
Class Days: Saturday, Sunday
Timings: 7:00 PM – 10:00 PM IST
Language: English
Teacher: Akhilesh Mishra
Prerequisites: Basic Linux
Module 1: Linux + DevOps Culture
Week 1: Linux & Shell Scripting Foundations + DevOps Fundamentals
- Linux filesystem: file permissions, ownership, users, groups
- Package management, process management, system monitoring
- Important files and directories: /etc/hosts, /etc/passwd, /etc/fstab, logs under /var/log
- SSH, key-based authentication, environment variables, shell profiles, secure server access
- Services and systemd: how applications run and are managed on Linux
- Shell scripting: variables, command line arguments, wildcards, I/O redirection, loops, conditionals, functions
- Building reusable automation scripts for real DevOps work
- DevOps culture discussion + SDLC
Projects
- Automated Backup & Disk Cleanup System
- Real-Time Log Monitoring & Alerting Script
Module 2: AWS Foundations
Week 2: AWS Networking, Security & Compute Foundations
VPC, Subnets, Route Tables, Internet Gateway, NAT Gateway
Public vs private networking, CIDR blocks, availability zones, production-grade network design
IAM fundamentals: users, groups, roles, policies, least-privilege access
Secure server access: Bastion Hosts, IAM Roles, AWS Systems Manager
VPC Endpoints, VPC Peering, Transit Gateway use cases
EC2 fundamentals: instance types, EBS volumes, AMIs, key pairs, monitoring
Running a 2-tier application on EC2: application tier plus PostgreSQL database
Nginx reverse proxy, Route53, Elastic IP, SSL certificates
Security groups for separate application and database tiers
How production teams structure AWS accounts, networking, and access control
Cost awareness from day one: right-sizing EC2, choosing instance families, spotting idle instances
Projects
- Production VPC from Scratch: Multi-AZ VPC with Public, Private App, and Private DB Subnets
- Secure EC2 Access using Bastion Host, IAM Roles, SSM Session Manager, and VPC Endpoints
- Deploy a 2-Tier Application on EC2 with Nginx, PostgreSQL, Route53, Elastic IP, and SSL
Week 3: AWS Storage, CDN & EC2 Scaling
Amazon S3: buckets, objects, versioning, encryption, access control
S3 storage classes and lifecycle policies for cost optimisation
Bucket policies, static website hosting, pre-signed URLs, S3 event notifications
CloudFront: caching, Origin Access Control, SSL certificates, cache invalidation, cost levers
Route53 and ACM basics for DNS and SSL
Production application architecture and high availability patterns
User data scripts, configuration management, application bootstrapping
Launch Templates, Auto Scaling Groups, scaling policies, zero-downtime deployments
Load Balancers: ALB vs NLB, listeners, target groups, health checks, routing
Connecting the EC2 application tier to load balancing and autoscaling end to end
Amazon RDS: networking, backups, Multi-AZ, Parameter Store integration
Auto Scaling and RDS instance sizing as cost levers
AI-assisted troubleshooting: using AI copilots to debug failures faster, and getting sharper at working with AI in day-to-day operations
Projects
- Production 2-Tier Application with ALB, Auto Scaling Group, RDS PostgreSQL, ACM, and Route53
- Auto Scaling Validation and Zero-Downtime Deployment under Load
- Static Website Hosting using S3 + CloudFront + Route53 + ACM SSL
Module 3: Containers, ECS, Terraform & CI/CD
Week 4: Containerization with Docker & Docker Compose
Why containers replaced VM-based deployments
Docker architecture: Engine, Images, Containers, Registries, Docker Hub
Building, tagging, storing, and sharing images across environments
Dockerfiles: image layers and caching
Container lifecycle, resource limits, logging, troubleshooting
Docker networking: bridge, custom networks, container-to-container communication, port mapping
Volumes, bind mounts, named volumes, persistent storage for stateful apps
Environment variables, secrets basics, configuration management
Docker Compose: multi-container apps with networking, volumes, environment-specific configs
Image optimisation: multi-stage builds and .dockerignore that cut registry and runtime cost
Projects
- Containerize a Flask + PostgreSQL Application using Docker Compose, custom networks, persistent volumes, and environment variables
- Migrate a VM-Based 2-Tier Application to Docker with Nginx, PostgreSQL, health checks, persistent storage, and production-ready image optimisation
Week 5: Running Containers in Production with AWS ECS
ECS architecture: clusters, services, task definitions, container networking, service discovery
Fargate vs EC2 launch types: when to choose each and the cost trade-off
Application Load Balancers, target groups, health checks, logging, monitoring
ECS security: IAM roles, Parameter Store, Secrets Manager
ECS vs Kubernetes: real-world case studies and decision frameworks
Production deployment patterns, high availability, scaling
Right-sizing task CPU and memory to control spend
PostgreSQL-backed application on ECS following production best practices
Load testing fundamentals: how applications behave under increasing traffic
Projects
- Deploy a Production 2-Tier Application on ECS with ALB, SSL, Route53, and RDS PostgreSQL
- Load Test the Application and Analyse Performance Bottlenecks under Production-Like Traffic
Week 6: Terraform Foundations & CI/CD for ECS Applications
Infrastructure as Code fundamentals
Providers, resources, variables, outputs, state management, dependency handling
Terraform planning, lifecycle management, safe change deployment
Deploy ECS infrastructure with Terraform instead of console clicks
GitHub Actions: workflows, jobs, runners, secrets, environments
CI/CD pipelines that build, test, and deploy automatically
GitHub: repositories, branches, pull requests, code reviews, collaboration workflows
GitHub best practices: branch protection, tagging, stashing, repository management
Container image versioning, deployment automation, rollback strategies
ECS autoscaling policies, CloudWatch alarms, monitoring dashboards
Tagging strategy in Terraform for cost allocation and accountability
Projects
- Deploy Complete ECS Infrastructure using Terraform: VPC, ALB, ECS, Route53, SSL, RDS
- Build a CI/CD Pipeline that Automatically Builds, Deploys, and Updates the ECS Application
Week 7: Microservices on ECS, Advanced Terraform & Advanced CI/CD
Microservices architecture patterns and service communication strategies
Multiple services on ECS with independent deployments and scaling policies
Advanced Terraform: modules, remote state, workspaces, imports, lifecycle management, multi-environment deployments
Reusable Terraform modules shared across teams and environments
Terraform best practices used by platform engineering teams in production
Advanced GitHub Actions: reusable workflows, composite actions, workflow templates, deployment approvals
Multi-environment pipelines for development, staging, and production
Cross-repository deployment: application and infrastructure code maintained separately
Load testing, autoscaling validation, production troubleshooting
Production-grade RDS: Multi-AZ, Read Replicas, Aurora patterns
Per-service cost visibility through tagging and scaling discipline
Projects
- Deploy a Production Microservices Application on ECS using Reusable Terraform Modules and Multi-Environment Infrastructure
- Build an Advanced GitHub Actions Platform with Reusable Workflows, Automated Deployments, Autoscaling, and Production Release Strategies
Module 4: Python for DevOps + Serverless
Week 8: Python Foundations + AWS Automation
Python environment setup, virtual environments, project structure
Data structures DevOps engineers actually use: dicts, lists, sets
os, subprocess: running shell commands from Python
File operations, JSON and YAML parsing
Error handling and exception management
Working with APIs using the requests module
boto3 architecture: sessions, clients vs resources, paginators
Environment-based config management: .env, os.environ
Python logging best practices
Lambda execution model: cold starts, warm starts, concurrency limits
Lambda triggers: S3, SQS, SNS, EventBridge
Lambda Layers: packaging dependencies, sharing code
Dead letter queues for failed invocations
IAM key rotation Lambda: EventBridge schedule, Secrets Manager, SES report
Daily cloud cost report Lambda: Cost Explorer data, per-service breakdown
Week 9: Serverless Automation
subprocess for running system tools from Python
ClamAV setup, freshclam, scan result parsing
File scanning automation running on ECS with S3 + SQS trigger
S3 event notification → SQS → Python consumer pattern
S3 object tagging: Clean/Infected
Multi-account AWS architecture: landing account vs clean account
SES email alerts for infected files
API Gateway + Lambda integration: proxy vs non-proxy
Multi-Lambda orchestration patterns: chaining, fan-out, fan-in
Lambda cost optimisation: right-sizing memory, reducing cold starts
EventBridge as the event bus
Week 10: Database Migration + Cost Automation with Python
Migration planning: pre-migration health check script
pg_dump and pg_restore from Python subprocess
pgsync for live data migration with minimal downtime
Data validation post-migration: row counts, checksum comparison
Containerising the migration script with Docker
Deploying a migration job on ECS Fargate as a one-off task
Lambda trigger for the ECS migration task
boto3 for pulling RDS and EC2 metrics via CloudWatch
Identifying rightsizing candidates: underutilised instances, oversized storage
Budget alerts: programmatic spend thresholds with notifications
Automated tagging enforcement: scanning for untagged resources
Building your own FinOps tooling in Python: the foundation for cost work woven through the rest of the bootcamp
Module 5: Kubernetes on AWS (EKS)
Week 11: Kubernetes Fundamentals + Local Clusters
The why behind Kubernetes: what broke before it existed
Control plane deep dive: API server, etcd, scheduler, controller manager
Worker node components: kubelet, kube-proxy, container runtime
Core objects: Pod, ReplicaSet, Deployment, Service
Setting up Kind locally, kubectl basics and everyday commands
ConfigMaps and Secrets: creating, mounting as env vars and volumes
Namespaces, labels, selectors, annotations
Resource requests and limits: correct sizing as the first line of cost control
Kubernetes DNS and service discovery internals
Liveness, readiness, and startup probes: real failure scenarios
Rolling upgrades and rollback strategies
HPA and VPA: pod autoscaling based on CPU, memory, custom metrics
Init containers and sidecar patterns
Pod Disruption Budgets for zero-downtime deployments
CrashLoopBackOff, OOMKilled: live debugging techniques
StatefulSets, DaemonSets, and Jobs
Week 12: CI/CD with OIDC + GitOps + Production EKS Foundation
GitOps fundamentals: why GitOps over push-based deployments
ArgoCD setup on Kind: apps, sync policies, health checks
End-to-end CI/CD: GitHub Actions builds image, ArgoCD deploys
ArgoCD App-of-Apps pattern, rollback, multi-environment GitOps
Prometheus + Grafana on Kind: request rate, pod health dashboards
EKS cluster setup via eksctl and AWS console
EKS add-ons: VPC CNI, CoreDNS, EBS CSI Driver, kube-proxy
IRSA: Kubernetes to AWS IAM with OIDC, no hardcoded credentials
AWS Load Balancer Controller with Helm
Ingress for internal and external traffic routing
ExternalDNS for automatic Route 53 record management
Domain and SSL/TLS termination with ACM
Week 13: 3-Tier App on EKS + Docker Optimisation
Running a 3-tier app: frontend + backend + RDS PostgreSQL on EKS
Database migrations using Kubernetes Jobs
Init containers for DB connection readiness checks
IRSA in practice: backend pod accessing Secrets Manager without credentials
External Secrets Operator: syncing Secrets Manager into Kubernetes Secrets
Ingress rules for routing traffic to frontend vs backend
Blue-Green deployment on EKS with weighted routing
Real troubleshooting: ImagePullBackOff, pending pods, service not reachable
StatefulSets deep dive: production patterns and failure recovery
PersistentVolume, PVC, StorageClass: static vs dynamic provisioning on EKS
EBS vs EFS: choosing the right storage for the workload, and the cost impact of each
Volume snapshots and backup strategies on EKS
Multi-stage Docker builds: drastically smaller production images
Distroless and minimal base images
Docker image optimisation: layer caching, build context, .dockerignore
Week 14: Microservices on EKS + Terraform for EKS
Production EKS cluster with Terraform: VPC, subnets, node groups, add-ons
Terraform module structure for EKS: separation of concerns
Managing dev/staging/prod with Terraform workspaces
IRSA setup via Terraform: no manual console steps
Terraform drift detection on EKS infrastructure
Node group configuration: instance types, spot vs on-demand for cost, taints and tolerations
EKS upgrade strategy with Terraform
Microservices design principles: bounded context, single responsibility
Splitting the monolith: frontend, order, inventory, and user service
Running PostgreSQL clusters on Kubernetes with CloudNativePG (CNPG): HA, automated failover, backups, and read replicas
Inter-service communication: ClusterIP vs headless vs service mesh
Network Policies for microservice traffic isolation between namespaces
Gateway API: advanced ingress routing
ArgoCD ApplicationSet for environment promotion across dev/staging/prod
Matrix builds in GitHub Actions for multiple microservices
Week 15: Full Observability Stack
Prometheus: metrics collection, PromQL, scrape configs, Prometheus Operator
Loki for log storage and querying: LogQL basics
Fluent Bit on EKS: log aggregation, filtering, routing to Loki
Grafana dashboards: Kubernetes cluster, app metrics, AWS resource metrics
Routing alerts to Slack and PagerDuty with grouping and silencing
CloudWatch Container Insights integration alongside Prometheus
OpenTelemetry for distributed tracing: instrumentation, collectors, exporters
Tracing a request across multiple microservices end to end
Jaeger or Tempo as tracing backend
Error budget dashboards in Grafana
Multi-window, multi-burn-rate alerting for SLOs
Log-based alerting in Grafana with Loki rules
Pod Security Admission: restricted, baseline, privileged modes
Week 16: Service Mesh + Autoscaling + Cost Optimisation
Service mesh fundamentals: what problems it actually solves
Istio installation and architecture: control plane, data plane, sidecars
mTLS between all microservices: automatic, no code changes
Traffic management: VirtualService, DestinationRule, Gateway
Canary deployments with Istio traffic splitting
Visualising service mesh traffic
Network Policies for zero-trust pod-to-pod communication
Egress controls and namespace isolation
Pod topology spread constraints for multi-AZ resilience
Karpenter architecture: how it differs from Cluster Autoscaler
NodePool and EC2NodeClass configuration
Karpenter bin packing and consolidation
KEDA: event-driven pod autoscaling on queue depth, Kafka lag, cron, and custom metrics
Cost optimisation with Spot + On-Demand mixed node fleets
EKS Auto Mode: what it is and when to use it
OpenCost and Kubecost: per-namespace, per-team, per-service cost attribution
Tagging strategy as cost governance: enforcing tags with Kyverno and OPA
Budget alerts, automated enforcement, and weekly FinOps reporting with rightsizing recommendations
Building a cost culture: making engineers aware of infrastructure costs
Kyverno policy enforcement: blocking deployments without resource limits
Module 6: DevSecOps + Kubernetes
Week 17: Shift-Left Security + Pipeline Hardening
DevSecOps mindset: where security fits in the SDLC
SAST with Semgrep: code-level vulnerability scanning in pull requests
DAST with OWASP ZAP: running against staging before every production release
SCA and dependency auditing with Trivy and Grype
Pre-commit secret scanning and GitHub secret scanning
Container supply chain security: Trivy blocking critical CVEs, image signing with Cosign, SBOM generation with Syft
IaC security scanning: Checkov linting Terraform and Kubernetes manifests
Secrets management in the pipeline: OIDC for AWS auth, External Secrets Operator
Building the full security pipeline end-to-end in GitHub Actions
Hard fail gates: nothing progresses if a gate does not pass
Writing Checkov exceptions with documented justification
Managing Trivy ignore files: accepting risk intentionally, not accidentally
Cosign signature verification in ArgoCD: blocking unsigned images
Dependency update automation: Dependabot and Renovate
Week 18: Kubernetes Runtime Security + Policy as Code + Zero Trust
Falco for runtime threat detection on EKS: custom rules for suspicious process execution, file access, and network activity
Falco alerting to Slack in real time
CIS Kubernetes Benchmark scanning with kube-bench
Network policies for zero trust between namespaces: default deny all, explicit allow only
Kubernetes audit logs: what is happening in your cluster and how to query it
Connecting every security tool into a single coherent pipeline
Cluster-side controls: Kyverno, Falco, network policies, pod security standards, kube-bench working together
Incident response workflow: what happens when Falco fires a critical alert
Security posture reporting: generating a weekly security health report
Module 7: SRE + Incident Response
Week 19: SRE Foundations + Chaos Engineering
Core SRE concepts: reliability, SLIs, SLOs, SLAs, error budgets, incidents, postmortems
SLI, SLO, SLA: precise definitions, writing measurable objectives
Error budgets: how they make deployment decisions instead of gut feel
Error budget policy: deployment freezes, negotiating reliability work vs feature work
DORA metrics: deployment frequency, lead time, MTTR, change failure rate
On-call culture and runbook discipline: what a good runbook looks like
Postmortem culture: blameless analysis, timeline reconstruction, RCAs that prevent recurrence
Chaos engineering philosophy: breaking things deliberately before they break unexpectedly
LitmusChaos on EKS: pod failure, network delay, CPU stress, disk fill experiments
Defining steady-state hypotheses and blast radius limits
Capacity planning basics: and the capacity vs cost trade-off
Building a production-ready SRE dashboard: error budget burn, DORA metrics, on-call health, alert volume
Reliability reviews: formal review of a service before it goes to production
Week 20: Incident Response, War Rooms & RCA
Incident lifecycle at scale: detection, triage, mitigation, resolution, postmortem, prevention
Alert routing design: routing the right alerts to the right team, avoiding alert fatigue
Runbook automation: using Python and Lambda to partially automate common incident responses
Auto-remediation patterns: when to automate and when to keep a human in the loop
Blast radius limiting in automation
Three live war room simulations with written RCAs
Kubernetes live debugging: the 10 most common senior-level interview scenarios
Building an incident timeline and writing an RCA that prevents recurrence
Module 8: MLOps + AIOps
Week 21: MLOps Foundations + ML Workloads on Kubernetes
Why MLOps exists: the gap between a notebook and a production system
The ML lifecycle: data, training, evaluation, deployment, monitoring, retraining
The platform engineer’s role in ML systems, and what is different from normal apps
Containerising ML workloads: dependencies, CUDA, reproducible images
Running ML workloads on EKS: CPU vs GPU node pools, taints and tolerations
GPU scheduling on Kubernetes: NVIDIA device plugin, time-slicing, MIG
Data versioning with DVC: tracking datasets and pipelines alongside code
Experiment tracking with MLflow: runs, parameters, metrics, artifacts
Projects
- Deploy an MLflow tracking server on EKS with an S3 artifact store and RDS backend
Week 22: Training Pipelines + Model Registry
Reproducible training pipelines: from a loose script to a repeatable pipeline
Argo Workflows or Kubeflow Pipelines for ML orchestration on Kubernetes
Multi-step pipelines: data prep, train, evaluate, register
MLflow Model Registry: versioning, stages, and promotion
Pipeline parameters, caching, and artifact passing between steps
Scheduling retraining jobs with cron and event triggers
Resource requests for training jobs: GPU sharing and cost control
Spot instances for training: checkpointing and handling interruptions
Projects
- Build an end-to-end training pipeline on EKS with Argo Workflows, MLflow tracking, and automatic model registration
Week 23: Model Serving + Inference at Scale
Model serving patterns: online, batch, and streaming
KServe and Seldon Core on EKS for production model serving
Packaging models for serving: ONNX, TorchServe, Triton Inference Server
Autoscaling inference: HPA on custom metrics, KEDA on queue depth, scale-to-zero
GPU inference: batching, multi-model serving, and the cost trade-offs
Canary and shadow deployments for models
A/B testing model versions with Istio traffic splitting
Inference latency, throughput, and cost optimisation
Projects
- Serve a model on EKS with KServe, autoscaling, and a canary rollout between two model versions
Week 24: Feature Stores + Data Pipelines + CI/CD for ML
Feature stores: why they exist, and running Feast on Kubernetes
Online vs offline features, and point-in-time correctness
Data pipelines that feed both training and serving
CI/CD for ML: testing data, models, and pipelines, not just code
GitHub Actions pipeline for ML: lint, test, train, validate, register, deploy
Model validation gates: accuracy thresholds and data drift checks before promotion
GitOps for ML: ArgoCD deploying model-serving manifests
Reproducibility and rollback for models in production
Projects
- Build a CI/CD pipeline that trains, validates, and deploys a model with automated quality gates and ArgoCD
Week 25: Model Monitoring + Drift Detection + ML Observability
Why models degrade in production: data drift, concept drift, training-serving skew
Monitoring model inputs and outputs with Prometheus and Grafana
Drift detection with Evidently or whylogs
Data quality monitoring on live traffic
Logging predictions for audit and for building retraining datasets
Alerting on model performance degradation, not just infrastructure health
Closing the loop: triggering retraining from drift signals
Cost monitoring for ML workloads: GPU utilisation and idle accelerators
Projects
- Add full monitoring and drift detection to a deployed model, with alerts and an automated retraining trigger
Week 26: AIOps Foundations + Intelligent Observability
What AIOps actually is: separating the hype from real operational value
The data foundation: metrics, logs, traces, and events as AIOps inputs
Anomaly detection on metrics: statistical baselines vs ML approaches
Detecting anomalies in time-series built on Prometheus data
Log anomaly detection: clustering and pattern extraction at scale
Reducing alert noise: correlation, grouping, and deduplication with ML
Local LLMs for ops with Ollama: running models on your own infrastructure
Why local LLMs matter for ops: data privacy, cost, and no vendor lock-in
Projects
- Set up Ollama on EKS and build an anomaly detection layer over Prometheus metrics
Week 27: LLM-Powered Operations + Log Analysis + RAG Runbooks
Using LLMs to analyse and summarise logs at scale
Building an LLM-based failure monitoring system on Kubernetes
Simulating realistic failures with Java application log generation
Parsing, classifying, and explaining errors with an LLM
RAG over your runbooks and postmortems: retrieval-augmented incident help
Embeddings, vector stores, and grounding answers in your own documentation
Prompt engineering for ops: structured outputs, guardrails, and reliability
Cost and latency trade-offs: local vs hosted models for ops workloads
Projects
- Build an LLM-powered log analysis and failure-explanation tool on EKS with a RAG runbook assistant
Week 28: Agentic AIOps + Auto-Remediation + Capstone & Career
AI agents for operations: when an agent genuinely helps and when it is dangerous
Designing safe auto-remediation: human-in-the-loop, blast radius limits, approvals
Connecting an LLM agent to ops tools: kubectl, AWS APIs, and runbooks
Automating triage: from alert, to enriched context, to a suggested fix
Guardrails, audit trails, and rollback for AI-driven actions
Where AIOps fails: over-automation, hallucination, and misplaced trust
Capstone: design and present a full MLOps or AIOps system end to end
Resume framework: action verbs, metric-driven project impact statements
How to present bootcamp work as production experience to a hiring manager
ATS optimisation: keywords, formatting, what breaks automated parsing
LinkedIn profile: headline, about section, skills, activity signals
GitHub portfolio cleanup: README structure, architecture diagrams, ADRs, decision logs
Senior interview preparation: scenario-based questions that actually get asked
System design for DevOps: designing CI/CD systems, logging pipelines, multi-region infrastructure
Final resume, LinkedIn, and GitHub portfolio review by Akhilesh
Projects
- Build a guarded auto-remediation agent that triages a real incident, proposes a fix, and acts only with approval
What You Get
28 weeks of live instruction: 56 classes, 3 hours each
Pre-bootcamp recordings for Linux and AWS fundamentals sent on enrolment
28+ real-world projects: every project production-grade, every failure debugged live
GitHub portfolio showing engineering judgment, not just tutorial code
AI-assisted troubleshooting skills woven through every module, so you debug faster and work better with AI copilots
Lifetime access to all recordings, code, notes, and resources
LivingDevOps Discord: cohort community and alumni network
Certificate of completion: DevOps + DevSecOps + SRE + MLOps + AIOps
Personal resume and LinkedIn review by Akhilesh
Referrals to relevant opportunities in the network where there is a genuine fit
Testimonials
Fahim Vazir
Abu
Balmiki Badatya
Sandeep
Hemant kumar
Ameet Khemani
Avinash V
Varsha Gore
Fahim Vazir
Abu
Balmiki Badatya
Sandeep
Hemant kumar
Ameet Khemani
Avinash V
Varsha Gore